



L’architettura e la progettazione dei robot abbracciano oggi una vasta gamma di funzioni e capacità, il che ha un impatto significativo sulla potenza di elaborazione e sulle risorse utilizzate per garantirla. In un ambiente controllato, come una gabbia di sicurezza, un robot di produzione richiede relativamente poche protezioni e può utilizzare strategie di controllo procedurale semplici.
I progettisti devono assicurarsi che il robot si arresti se la gabbia viene aperta o se i pezzi non sono posizionati come previsto. Tuttavia, molte delle sfide legate alla sicurezza possono essere affrontate mediante l’impiego di interblocchi hardware piuttosto che complesse combinazioni di sensori d’immagine e software. I requisiti chiave dell’elaborazione in questo contesto sono quelli di garantire un controllo del movimento efficiente e preciso. Questo richiede principalmente l’uso di microcontrollori o processori di segnali digitali per gestire il flusso di energia ai motori e agli altri attuatori.
L’evoluzione delle unità di microcontrollo.
I progetti dei robot di produzione convenzionali tendono a essere poco flessibili. Ogni programma deve essere programmato, simulato e testato a lungo prima di poter procedere. Nella produzione, gli utenti desiderano che i robot siano più flessibili, in modo da poterli assegnare rapidamente a compiti diversi. Devono inoltre essere in grado di muoversi all’interno del reparto di produzione, il che comporta la necessità di operare al di fuori della gabbia di sicurezza. Questi requisiti richiedono una maggiore potenza di elaborazione per fornire ai robot la capacità di navigare senza collisioni accidentali con gli oggetti o danneggiare gli astanti.
Di conseguenza, i robot devono essere in grado di elaborare gli input dei sensori in tempo reale e di prendere decisioni intelligenti al volo, a seconda delle circostanze. Più i robot si allontanano dalla gabbia di sicurezza e più interagiscono con gli esseri umani, maggiore sarà la potenza di elaborazione di cui avranno bisogno quando si troveranno al di fuori dell’ambiente relativamente controllato dell’officina. I robot di servizio e i droni per le consegne devono essere in grado di reagire in modo intelligente a situazioni complesse.
In questi scenari avanzati, emerge chiaramente la necessità di una maggiore sofisticazione del software, che deve avanzare di pari passo con la velocità di calcolo. Il progettista ha un alto grado di flessibilità nella scelta di come fornire la potenza di elaborazione richiesta, non solo in termini di fornitori, ma anche di architettura complessiva.
L’uso dei microcontrollori
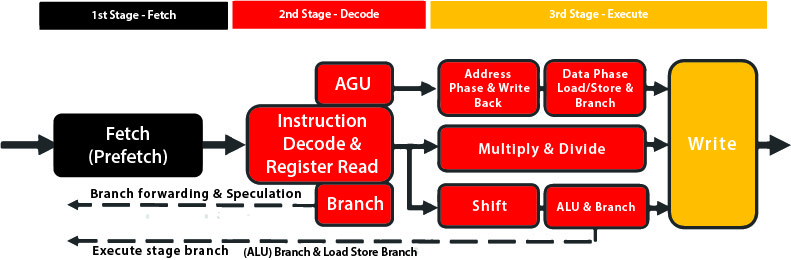
L’unita del microcontrollore (MCU) è stato predominante per molti anni nelle applicazioni dei robot di base. Il cuore dell’MCU è il microprocessore. Inizialmente, i nuclei dei microprocessori nelle MCU erano ottimizzati per operazioni aritmetiche e di controllo a livello logico semplici, ma dalla loro introduzione, quasi 50 anni fa, le prestazioni e le capacità di gestione dei dati sono notevolmente migliorate. Oggi, i core dei microprocessori che operano nativamente su parole di dati a 32 bit e che offrono caratteristiche di prestazione come il pipelining e l’architettura Harvard sono disponibili a un livello di costo che permette anche ai sistemi più semplici di utilizzarli.
In un tipico core di microprocessore a 32 bit, come l’ARM Cortex-M3, è presente una pipeline di istruzioni che separa l’esecuzione dei comandi in una serie di fasi. Nella pipeline del M3, innanzitutto, l’istruzione viene recuperata da una cache locale. Se l’istruzione non è presente nella cache, deve essere prima caricata dalla memoria principale. Una volta nella pipeline, i byte dell’istruzione vengono decodificati per determinare quali unità funzionali devono essere attivate per eseguire l’istruzione. Infine, si procede all’esecuzione.
Pipelining e gestione degli interruttori
Il pipelining viene utilizzato per mitigare effetti come la latenza della memoria, consentendo di sovrapporre l’esecuzione di multiple istruzioni e contribuendo ad aumentare la velocità dell’orologio, poiché richiede meno passaggi logici per ciclo. I processori più veloci utilizzano pipeline più lunghe, che possono avere dieci o più fasi. Tuttavia, una svantaggio delle pipeline lunghe è l’alta latenza di diramazione. Quando si verifica un salto di istruzione, è necessario del tempo per riempire nuovamente la pipeline con le istruzioni necessarie per la nuova direzione.
Il supporto per gli interruzioni consente al core del processore di sospendere temporaneamente l’esecuzione del programma principale per gestire altre attività. La gestione delle interruzioni è un componente essenziale per le applicazioni che richiedono una risposta in tempo reale agli eventi. Senza di essa, il codice del programma dovrebbe costantemente monitorare gli eventi esterni, comportando uno spreco significativo di capacità di calcolo.
Microprocessori per i progettisti di robot

Lo schema di priorità utilizzato dalla maggior parte dei core del processore consente di ignorare gli interrupt provenienti da periferiche relativamente meno importanti, mentre il processore si occupa delle routine critiche, come il trasferimento del controllo da un’attività all’altra o l’elaborazione di interrupt critici. Il risultato è un’architettura altamente flessibile, in grado di gestire una varietà di applicazioni in tempo reale.
Una variante importante e specializzata del microprocessore per i progettisti di robot è il processore di segnale digitale (DSP). Si tratta di un nucleo del processore che aggiunge istruzioni e hardware ottimizzati per eseguire algoritmi di elaborazione del segnale, come filtri e trasformate veloci di Fourier. Queste istruzioni includono operazioni di moltiplicazione e addizione veloci e fuse, che sono presenti praticamente in tutti gli algoritmi DSP. Poiché il codice DSP opera su strutture di dati come matrici e vettori, è relativamente semplice parallelizzare il lavoro. Ciò ha portato all’implementazione di unità di esecuzione a istruzione singola e dati multipli (SIMD), che eseguono le stesse operazioni, come moltiplicazioni e addizioni, su più elementi di un array contemporaneamente. Il risultato è una notevole velocità incrementata con un relativo basso aumento di complessità e costi.
Un MCU (Microcontroller Unit) comprende una serie di periferiche integrate disposte attorno al nucleo del processore. In genere, in un MCU industriale o robotico, le periferiche vanno dagli array di memoria alle unità timer-trigger avanzate, utilizzate per alleggerire il carico della modulazione di larghezza degli impulsi (PWM) sul microprocessore. La PWM è un componente fondamentale in quasi tutte le strategie di controllo dei motori e quindi svolge un ruolo essenziale nella progettazione robotica. Altri dispositivi System-on-Chip (SoC) aggiungono ulteriori funzionalità attorno a un MCU, come ricetrasmettitori wireless, logica di crittografia e autenticazione dedicata, nonché acceleratori grafici.
Controllo e hardware
L’impiego di periferiche intelligenti illustra anche un principio di progettazione sempre più rilevante per i robot: sfruttare il controllo distribuito e l’accelerazione hardware. È possibile utilizzare un microprocessore per implementare il controllo PWM, ma spesso ciò rappresenta una scorretta allocazione delle risorse. Il cuore del problema risiede nel fatto che il software deve commutare ripetutamente l’alimentazione tra i transistor del mezzo ponte, che controlla il flusso di corrente verso il motore, seguendo intervalli pre-programmati. Gli interrupt provenienti da un orologio o da un contatore in tempo reale possono facilmente attivare i gestori per commutare lo stato di alimentazione e configurare quindi il timer per il ciclo successivo. Tuttavia, ciò comporta una frequenza elevata di interrupt per una sequenza di operazioni estremamente semplice.
Un controllore PWM combina un timer e una logica di commutazione, eliminando la necessità di interrompere il core del microprocessore per ogni operazione di commutazione. Il software deve solo aggiornare periodicamente i timer per impostare il duty cycle PWM richiesto. Grazie a una quantità relativamente ridotta di logica aggiuntiva, che può operare in modo indipendente dal processore per periodi di tempo considerevoli, l’efficienza del software migliora notevolmente. Questa architettura condivide un tema comune con altri meccanismi di scarico dell’hardware che diventeranno sempre più importanti nella progettazione robotica. Le periferiche hardware gestiscono eventi frequenti in tempo reale, mentre il software definisce la politica per tali periferiche.
Nel caso delle periferiche hardware, i progettisti sono vincolati alle funzioni offerte dai fornitori di circuiti integrati. Tuttavia, l’inclusione di sequenziatori basati su macchine a stati hardware può aumentare la loro flessibilità. Ad esempio, questi sequenziatori possono leggere valori da un convertitore A/D, trasferire dati direttamente nella memoria principale utilizzando l’accesso diretto alla memoria (DMA) e impostare o ricaricare timer, tutto ciò senza coinvolgere il nucleo della CPU. Tuttavia, le opzioni rimangono limitate.
FPGA nella robotica
Il field-programmable gate array (FPGA) offre un mezzo per creare periferiche hardware personalizzate ottimizzate per specifiche funzioni di controllo robotico e apprendimento automatico.
Il nucleo della maggior parte delle architetture FPGA è composto da una tabella di ricerca programmabile che può essere configurata per implementare qualsiasi funzione logica esprimibile come una tabella di verità. Utilizzando interruttori programmabili nel tessuto di interconnessione, le tabelle di ricerca vengono interconnesse tra loro attraverso complessi circuiti logici combinazionali. In genere, ciascuna tabella di ricerca è accompagnata da uno o più registri e da una logica di supporto aggiuntiva, come gli ingressi e le uscite della catena di trasporto, al fine di agevolare l’implementazione efficiente di sommatori aritmetici. Insieme, queste funzioni costituiscono un blocco logico che viene replicato più volte nell’FPGA.
Uno svantaggio rispetto alla logica completamente personalizzata è che l’efficienza del silicio è notevolmente inferiore. L’area di silicio richiesta per ospitare un circuito logico all’interno di un fabric FPGA è da 10 a 20 volte maggiore rispetto a un’implementazione personalizzata basata su celle standard.
Tuttavia, la maggior parte delle FPGA supporta la riprogrammazione dell’array logico anche mentre il sistema è in esecuzione. Ciò consente di condividere le risorse, caricando dinamicamente gli acceleratori nel fabric solo quando sono necessari. Questo approccio offre anche una maggiore flessibilità per il progetto finale, il quale può supportare nuovo hardware e funzionalità aggiuntive.
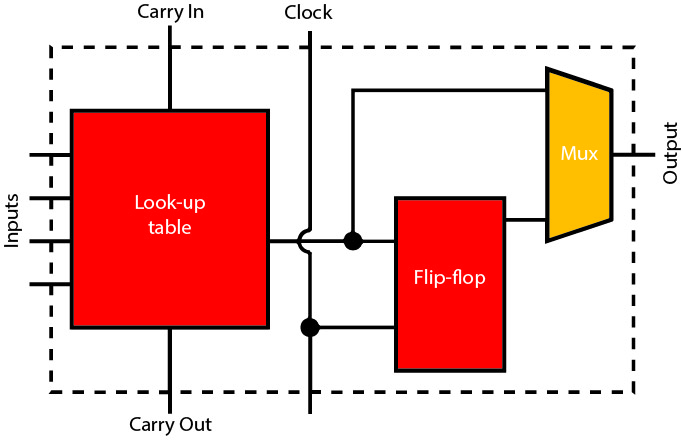
Dall’introduzione degli anni ’80, le FPGA hanno acquisito ulteriori caratteristiche che ne migliorano la densità complessiva. I blocchi di memoria consentono di creare buffer e cache vicino alla logica programmabile. A questi si sono aggiunti più recentemente i motori DSP. In molti casi, i motori DSP sono implementati con un approccio a blocchi, composti da unità da 8 o 16 bit, che possono essere combinati per supportare tipi di dati a più alta precisione.
Le unità DSP rendono le FPGA particolarmente adatte all’elaborazione dei dati provenienti da sensori che generano grandi quantità di dati, come telecamere, radar e altri tipi di sensori di immagini. Un’applicazione tipica consiste nell’utilizzare una combinazione di unità DSP e acceleratori logici per gestire algoritmi come il warping delle immagini e la compensazione dell’illuminazione, al fine di fornire input più coerenti alle funzioni di machine-learning e simili. Queste funzioni possono essere coordinate da core di microprocessori personalizzati implementati nel tessuto programmabile, che agiscono come microsequencer per le diverse primitive di elaborazione.
Sfruttare GPU, VPU e multiprocessing
Un’altra opzione, specialmente per le attività di elaborazione delle immagini, è l’utilizzo di un’unità di elaborazione grafica (GPU) o un’unità di elaborazione della visione (VPU). Queste unità contengono motori DSP altamente parallelizzati e ottimizzati per l’elaborazione delle immagini. Per i robot che richiedono elevati livelli di consapevolezza ambientale, queste unità dedicate possono essere combinate con più CPU, talvolta sullo stesso chip, come un SoC eterogeneo multi-core.
L’uso del multiprocessamento può anche migliorare l’affidabilità e la sicurezza complessiva. Un problema comune per qualsiasi progetto basato su computer è la dipendenza da tecnologie di memoria vulnerabili alle radiazioni ionizzanti. Quando le radiazioni ionizzanti colpiscono il substrato di silicio di un circuito integrato, innescano una cascata di elettroni liberi che cambiano lo stato logico di un transistor. Nei transistor a circuito combinatorio, l’effetto è solitamente transitorio e si verifica solo raramente.
Tuttavia, le memorie e i registri sono più vulnerabili alle modifiche a causa del modo in cui riciclano il loro contenuto per evitare la dispersione dei dati memorizzati. I codici di correzione e rilevazione degli errori (ECC) aiutano a gestire questo problema. La probabilità di errore in un singolo evento aumenta con la densità della memoria, rendendo il problema sempre più critico man mano che i circuiti integrati continuano a seguire la legge di Moore. Inoltre, l’ECC potrebbe non rilevare tutti gli errori, il che potrebbe portare a un’applicazione che opera su dati errati e, alla fine, causare un fallimento del sistema di controllo. In un robot che interagisce con il pubblico, situazioni del genere non possono verificarsi.
Tecniche di ridondanza e la progettazione di processori diversi affrontano questo problema.
Queste tecniche garantiscono che singoli processori supervisionino il lavoro degli altri.
I processori possono essere dello stesso tipo ed eseguire lo stesso codice. La logica di controllo confronta i risultati ottenuti e utilizza un sistema di votazione per determinare quale operazione consentire o richiedere che venga eseguita nuovamente finché i processori non sono in accordo.

L’uso di tre processori con un sistema di votazione a maggioranza è più costoso ma meno invasivo, poiché la ripetizione delle operazioni può causare ritardi indesiderati. La ridondanza modulare può essere implementata anche a livello di gate.
Non è necessario che i processori in una configurazione ridondante siano identici. Alcune architetture prevedono che un processore meno performante funga da motore di controllo. Invece di eseguire lo stesso software, si limita a eseguire controlli di coerenza e a forzare una nuova esecuzione se un controllo fallisce o, in casi più estremi, un reset completo.
Per ridurre al minimo le possibilità che errori sistematici di progettazione si insinuino nell’equazione, i processori duplicati possono essere progettati e implementati in modi diversi. Questa è una tecnica utilizzata in alcuni SoC multi-core sviluppati per i sistemi di sicurezza automobilistici.
Le opzioni architetturali per i progettisti di robot sono ora molto ampie.
Queste opzioni li portano da progetti semplici a macchine altamente flessibili, capaci di reagire in modo intelligente a problemi e ostacoli, e di continuare a funzionare senza intoppi.




