



Roboterarchitekturen und -entwicklungen decken mittlerweile zahlreiche Funktionen und Fähigkeiten ab. Das wirkt sich massgeblich auf die Verarbeitungsleistung und deren technische Voraussetzungen aus. Im kontrollierten Bereich des Sicherheitskäfigs benötigt der Produktionsroboter relativ wenige Schutzvorkehrungen und kann einfache Steuerstrategien realisieren.
Der Entwickler muss nur dafür sorgen, dass der Roboter beim Öffnen des Käfigs oder bei falsch ausgerichteten Teilen anhält. Selbst dann lassen sich viele Sicherheitsfunktionen mit einfachen mechanischen Verriegelungen umsetzen und kommen ohne komplexe Bildverarbeitungssensoren und Softwareprogramme aus. Die wichtigste Aufgabe der Datenverarbeitung ist die effiziente, präzise Bewegungssteuerung. Dazu werden in erster Linie Mikrocontroller oder digitale Signalprozessoren benötigt, die für die Bestromung der Motoren und Stellglieder sorgen.
Die Entwicklung der Mikrocontroller-Einheiten
Konventionelle Produktionsroboter sind eher unflexibel. Jedes Programm muss einzeln programmiert, simuliert und umfangreich getestet werden, bevor der Roboter an die Arbeit geht. In der Fertigung muss der Roboter flexibler sein, damit er innerhalb kurzer Zeit für neue Aufgaben vorbereitet werden kann. Darüber hinaus muss er seinen Sicherheitskäfig verlassen können, um sich innerhalb des Fertigungsbereichs zu bewegen. All das verlangt nach mehr Verarbeitungsleistung, damit der Roboter ohne versehentliche Zusammenstösse mit Gegenständen oder Personen navigieren kann.
Der Roboter muss die Sensordaten also in Echtzeit verarbeiten und intelligente Sofortentscheidungen treffen, um sich auf wechselnde Bedingungen einzustellen. Je weiter sich der Roboter vom Sicherheitskäfig entfernt, und je mehr er mit dem Menschen interagiert, desto mehr Prozessorleistung ist gefordert, weil er sich zusehends ausserhalb der relativ gut kontrollierten Umgebung des Produktionsbereichs bewegt. Wartungsroboter und Lieferdrohnen müssen intelligent auf komplexe Situationen reagieren können.
Für solch fortgeschrittene Szenarien wird eine raffinierte Software benötigt, was sich mit dem angesprochenen Datendurchsatz deckt. Bei der Bereitstellung der notwendigen Prozessorleistung hat der Entwickler eine grosse Auswahl an Anbietern und Architekturen.
Der Einsatz von Mikrocontrollern
The microcontroller unit (MCU) has for many years been the computational element of choice for basic robots. The core of the MCU is the microprocessor. Initially, the microprocessor cores in MCUs were optimised for simple arithmetic and logic-level control, but since their introduction almost 50 years ago, the performance and data-handling capabilities have expanded dramatically. Today, microprocessor cores that natively operate on 32-bit data words and which offer performance features such as pipelining and Harvard architecture are now offered at a cost level that allows even simple systems to make use of them.
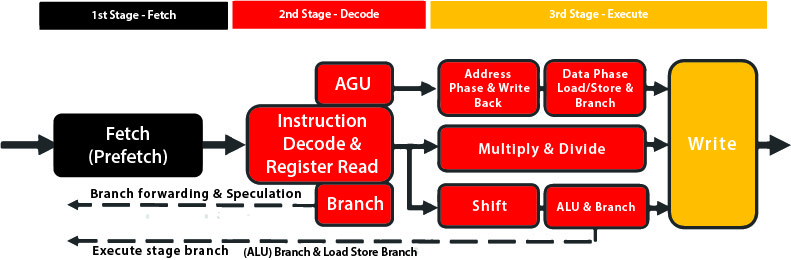
Bei einem typischen 32-Bit-Mikroprozessor-Core wie dem ARM Cortex-M3 gibt es eine Befehls-Pipeline, die die Ausführung von Befehlen in verschiedene Phasen aufteilt. In der M3-Pipeline wird der Befehl zunächst aus einem lokalen Cache geholt (Fetch). Falls sich der Befehl nicht im Cache befindet, muss er aus dem Hauptspeicher geladen werden. Sobald er in der Pipeline ist, werden die Befehlsbytes entschlüsselt, um auswerten zu können, welche Funktionseinheiten zur Ausführung des Befehls bestromt werden müssen. Dann wird der Befehl ausgeführt.
Pipelining und Unterbrechungsbehandlung
Durch das Pipelining lässt sich beispielsweise die Latenz des Speichers ausgleichen. So können mehrere Befehle überlappt und die Taktrate beschleunigt werden, da pro Zyklus weniger logische Schritte nötig sind. Schnellere Prozessorkerne brauchen längere Pipelines, die aus zehn oder mehr Stufen bestehen. Der Nachteil einer langen Pipeline ist die hohe Sprunglatenz. Wenn ein Sprung ausgeführt wird, dauert es eine Weile, bis die Pipeline mit den für den neuen Sprung benötigten Befehlen gefüllt ist.
Da der Prozessorkern Interrupts unterstützt, kann er die Ausführung des Hauptprogramms vorübergehend aussetzen und andere Aufgaben bearbeiten. Die Interruptverarbeitung ist eine Schlüsselkomponente bei allen Anwendungen, die Echtzeitreaktionen auf Ereignisse erfordern. Ohne sie müsste der Programmcode Loops enthalten, die kontinuierlich Information zu externen Ereignissen abrufen, was unnötig viel Rechenleistung in Anspruch nehmen würde.
Mikroprozessoren für Roboterentwickler

Bei den meisten Prozessorkernen können Interrupts von relativ unwichtigen Peripheriegeräten dank eines Prioritätsschemas ignoriert werden, während sich der Prozessor mit den kritischen Routinen befasst (z. B. den Übergang der Steuerung von einer Aufgabe zur nächsten oder die Eingangssignale eines kritischen Interrupts). Das führt zu einer äusserst flexiblen Architektur, die mit vielen verschiedenen Echtzeitanwendungen zurechtkommt.
Eine wichtige, spezialisierte Mikroprozessorvariante für Roboterentwickler ist der digitale Signalprozessor (DSP). Dieser Prozessorkern beinhaltet zusätzliche Befehle und Ausführungshardware, die für signalverarbeitende Algorithmen wie Filter und schnelle Fourier-Transformationen optimiert sind. Solche Befehle beinhalten schnelle FMA-Operationen (Fused-Multiply-Add), wie sie in praktisch allen DSP-Algorithmen vorkommen. Da der DSP-Code auf Matrizen, Vektoren und ähnlichen Datenstrukturen basiert, lässt sich die Arbeit relativ leicht parallelisieren. Diese Tatsache hat zur Implementierung von SIMD-Ausführungseinheiten (Single Instruction Multiple Data) geführt, die identische Vorgänge – z. B. Multiply-Adds – auf mehreren Elementen eines Arrays gleichzeitig ausführen. Das Ergebnis ist eine erheblich höhere Geschwindigkeit bei vergleichsweise geringer Komplexität oder Kostensteigerung.
An MCU includes a number of integrated peripherals that are arranged around the processor core. Typically, in an industrial or robotics-oriented MCU, the peripherals range from memory arrays to advanced timer-trigger units, which are used to offload the burden of pulse width modulation (PWM) from the microprocessor. PWM is a core component of almost all motor-control strategies and so features prominently in robotic design. Other system-on-chip (SoC) devices add more features around an MCU such as wireless transceivers, dedicated encryption and authentication logic and graphics accelerators.
Steuerung und Hardware
Die Verwendung intelligenter Peripheriegeräte veranschaulicht ausserdem ein wichtiges Konstruktionsprinzip in der Robotik: die Nutzung von Beschleunigern für dezentrale Steuerung und Hardware. Ein Mikroprozessor ermöglicht die PWM-Steuerung, stellt oft aber keine gute Ressourcenverteilung dar. Das Problem liegt darin, dass die Software die Spannung immer wieder zwischen den Transistoren in der Halbbrücke umschalten muss, welche die Stromversorgung eines Motors nach vorprogrammierten Intervallen steuert. Interrupte von einer Echtzeituhr oder einem Zähler können Handler auslösen, um den Bestromungszustand umzuschalten, und dann den Timer für den nächsten Zyklus konfigurieren. Trotz der sehr einfachen Abfolge von Vorgängen entsteht jedoch eine hohe Interruptfrequenz.
Eine PWM-Steuerung kombiniert Timer und Schaltlogik, weshalb der Mikroprozessor-Core nicht bei jedem Schaltvorgang unterbrochen werden muss. Die Software muss die Timer nur regelmässig aktualisieren, um das benötigte PWM-Tastverhältnis einzustellen. Dank der vergleichsweise geringen zusätzlichen Logik, die unabhängig vom Prozessor über lange Zeit zur Verfügung steht, wird die Softwareeffizienz erheblich verbessert. Die Architektur hat eine Gemeinsamkeit mit anderen Hardware-Entlastungsmechanismen, die für die Robotik zusehends an Bedeutung gewinnen werden. Die Hardware-Peripherie befasst sich mit häufigen Ereignissen in Echtzeit, während die Software die Strategie für die Peripherie festlegt.
Bei der Hardware-Peripherie sind die Entwickler an die von den Halbleiteranbietern bereitgestellten Funktionen gebunden, auch wenn sie durch die Einbindung von Ablaufsteuerungen auf der Basis von Zustandsautomaten an Flexibilität gewinnen. Ablaufsteuerungen können beispielsweise Werte aus einem AD-Wandler lesen, Datenwerte per Speicherdirektzugriff (DMA, Direct Memory Access) an den Hauptspeicher übertragen und Timer einstellen bzw. reloaden, ohne dass der CPU-Core dafür bemüht wird. Dennoch bleiben die Möglichkeiten begrenzt.
FPGA in der Robotik
Mit einem feldprogrammierbaren Gate-Array (FPGA) können anwendungsspezifische Hardware-Peripheriegeräte erzeugt werden, die sich für spezielle Robotersteuerungs- und Maschinenlernfunktionen optimieren lassen.
Den Kern der meisten FPGA-Architekturen bildet eine programmierbare Lookup-Tabelle, die für die Umsetzung jeder als Wahrheitstabelle darstellbaren Logikfunktion konfiguriert werden kann. Die Lookup-Tabellen werden über programmierbare Schalter im Interconnect-Fabric zu komplexen kombinatorischen Logikschaltungen verdrahtet. Jede Lookup-Tabelle wird typisch von mindestens einem Register und einer zusätzlichen Unterstützungslogik (z. B. Carry-Chain-Eingänge und Ausgänge) begleitet, um die effiziente Implementierung arithmetischer Addierer zu ermöglichen. Gemeinsam ergeben diese Funktionen einen Logik-Baustein, der innerhalb des FPGA mehrfach repliziert wird.
Ein Nachteil im Vergleich zu einer vollständig anwendungsspezifischen Logik ist der erheblich geringere Wirkungsgrad des Siliziums. Die Unterbringung einer Logikschaltung auf einem FPGA-Fabric beansprucht 10 bis 20 Mal mehr Siliziumfläche als bei einer anwendungsspezifischen Implementierung mit Standardzelle.
Allerdings unterstützen die meisten FPGAs eine Umprogrammierung des Logik-Arrays selbst bei Systemen in Betrieb. Dadurch sind Ressourcen gemeinsam nutzbar, indem Beschleuniger nur bei Bedarf dynamisch in den Fabric geladen werden. Dieses Verfahren sorgt auch für mehr Flexibilität im finalen Konstrukt, welches neue Hardware und Zusatzfunktionen unterstützen kann.
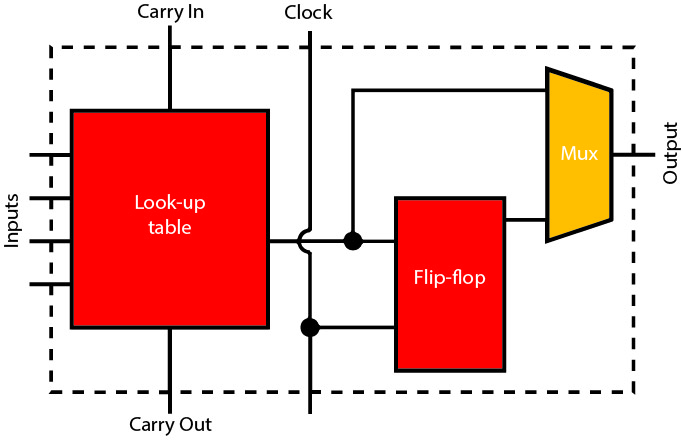
Seit ihrer Einführung in den 1980er Jahren sind FPGAs um weitere Funktionen ergänzt worden, die zu einer Verbesserung der Gesamtdichte führen. Mit Speicherblöcken lassen sich Puffer und Caches nah an der programmierbaren Logik erzeugen. Diese wurden in jüngerer Vergangenheit mithilfe von DSP-Engines kombiniert. In vielen Fällen werden die DSP-Engines als Bausteine aus 8- oder 16-Bit-Einheiten implementiert, sodass sie in Kombination präzisere Datentypen unterstützen können.
DSP units make FPGAs highly suitable for processing the inputs from sensors that produce large amounts of data, such as cameras, radar and other types of image sensors. A typical application is to use a combination of DSP units and logic accelerators to handle algorithms such as image warping and lighting compensation that provide more consistent inputs to machine-learning and similar functions. These functions can be coordinated by custom microprocessor cores implemented in the programmable fabric, which act as microsequencers for the different processing primitives.
Nutzung von GPUs, VPUs und Multi-Processing
Eine weitere Möglichkeit besteht insbesondere für bildverarbeitende Aufgaben in der Verwendung von Grafikprozessoren (GPU) oder Vision Processing Units (VPU). Diese enthalten hochgradig parallelisierte DSP-Engines, die für die Bildverarbeitung optimiert sind. Bei Robotern, die ein sehr hohes Mass an Umgebungserkennung erfordern, können diese Einheiten mit mehreren CPUs kombiniert werden – etwa auf demselben Chip als heterogenes Multi-Core-SoC.
Das Multiprocessing lässt sich auch zur Verbesserung der allgemeinen Zuverlässigkeit und Sicherheit nutzen. Ein Problem bei allen computerbasierten Auslegungen ist die Abhängigkeit von Speichertechnologien, die empfindlich auf ionisierende Strahlung reagieren. Wenn ionisierende Strahlung auf das Silizium eines integrierten Schaltkreises trifft, erzeugt es im Halbleiter freie Ladungsträger, die den logischen Zustand eines Transistors umkehren. In Schaltnetztransistoren ist diese Wirkung meist nur vorübergehend und nur selten zu beobachten.
Speicher und Register reagieren jedoch empfindlicher auf die Veränderung, weil sie ihre Inhalte recyceln, um den Verlust gespeicherter Daten zu verhindern. Mit ECC-Codes (Error Checking and Correction, Fehlerkorrekturverfahren) lässt sich das Problem beheben. Die Wahrscheinlichkeit einer einmaligen Störung steigt parallel zur Speicherdichte und wird dadurch zum wachsenden Problem, da die integrierten Schaltkreise weiterhin nach dem mooreschen Gesetz skalieren. Ausserdem ist nicht gesagt, dass ECC alle Fehler findet. Das kann dazu führen, dass das Programm mit falschen Daten arbeitet und es letztlich zu einem Ausfall der Steuerung kommt. Bei Robotern, die mit der Öffentlichkeit interagieren, darf das keinesfalls passieren.
Redundanztechniken und verschiedene Prozessordesigns
Redundanzen und ähnliche Verfahren behandeln das Problem, indem einzelne Prozessoren die gegenseitigen Funktionen überprüfen.
Die Prozessoren können vom Typ her identisch sein und mit demselben Code arbeiten. Eine Prüflogik vergleicht die Ausgangssignale und ermittelt entweder per Abstimmung, welcher Vorgang zulässig ist, oder fordert die Wiederholung der Vorgänge, bis die Prozessoren übereinstimmen.

Drei Prozessoren mit Mehrheitsabstimmung sind teurer, dafür aber weniger störend, weil die Wiederholung von Vorgängen unerwünschte Verzögerungen verursachen kann. Modulare Redundanz kann auch auf Gate-Ebene implementiert werden.
Die Prozessoren in einer redundanten Anordnung müssen nicht typgleich sein. Bei einigen Architekturen dient ein weniger leistungsfähiger Prozessor als Prüf-Engine. Statt dieselbe Software zu verwenden, führt er nur Konsistenzprüfungen durch und erzwingt bei einer nicht bestandenen Prüfung die erneute Ausführung, oder in extremeren Fällen gar einen kompletten Reset.
Um das Risiko systematischer Auslegungsfehler in der Gleichung möglichst gering zu halten, können duplizierte Prozessoren entwickelt und unterschiedlich implementiert werden. Dieses Verfahren kommt bei einigen Multicore-SoCs zum Einsatz, die für Sicherheitssysteme im Automobilbau entwickelt wurden.
Architektonische Optionen für Roboterdesigner
Dementsprechend erstreckt sich das Angebot an Architekturen für Roboterentwickler heute vom einfachen Aufbau bis hin zu hochflexiblen Maschinen, die intelligent auf Probleme und Störungen reagieren und den reibungslosen Systemablauf gewährleisten.




