



Robot architecture and design now spans a wide range of functions and abilities. This strongly affects the processing power and what is used to deliver it. Within the controlled environment of a safety cage, a production robot needs relatively few safeguards and can make use of simple procedural control strategies.
Designers need to ensure that the robot will stop if the cage is opened, or if parts are not aligned as expected. Even so, many of the safety challenges can be met using simple hardware interlocks rather than complex combinations of image sensors and software. The key processing requirements are to ensure efficient and precise control of motion. This primarily demands the use of microcontrollers or digital signal processors to manage the flow of power to motors and other actuators.
The evolution of microcontroller units
Conventional production robot designs tend to be inflexible. Each of their programs needs to be programmed, simulated and tested extensively before the robot is allowed to proceed. In manufacturing, users want robots to be more flexible so that they can be quickly assigned to different tasks. They also need to be able to move around the production floor, which entails operation outside the safety cage. These requirements call for greater processing power to provide the robot with the ability to navigate without accidentally colliding with objects or harming bystanders.
As a result, robots need to be able to process sensor input in real time and make intelligent decisions on the fly as circumstances change. The further robots move away from the safety cage and the more they interact with humans, the more processing power they will need as they move beyond the relatively controlled environment of the shop-floor. Service robots and delivery drones need to be able to react intelligently to complex situations.
In these more advanced scenarios there is a clear need for greater software sophistication, which goes hand in hand with computational throughput. The designer has a high degree of choice as to how to supply the required processing power, not just in terms of suppliers but overall architecture.
The use of microcontrollers
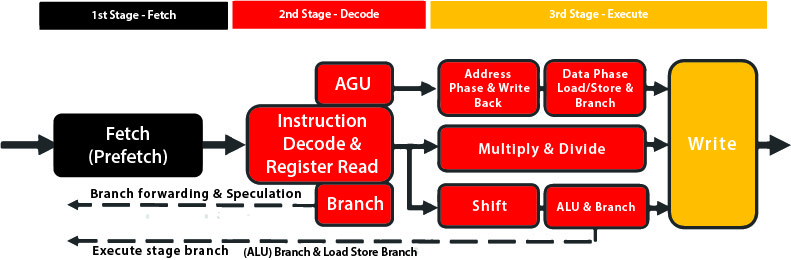
The microcontroller unit (MCU) has for many years been the computational element of choice for basic robots. The core of the MCU is the microprocessor. Initially, the microprocessor cores in MCUs were optimised for simple arithmetic and logic-level control, but since their introduction almost 50 years ago, the performance and data-handling capabilities have expanded dramatically. Today, microprocessor cores that natively operate on 32-bit data words and which offer performance features such as pipelining and Harvard architecture are now offered at a cost level that allows even simple systems to make use of them.
In a typical 32-bit microprocessor core, such as the ARM Cortex-M3, there is an instruction pipeline that separates execution of commands into a number of phases. In the M3 pipeline, first the instruction is fetched from a local cache. If the instruction is not in the cache, it first must be loaded from the main memory. Once in the pipeline, the instruction bytes are decoded to evaluate which functional units need to be activated to execute the instruction. Finally, execution takes place.
Pipelining and interrupt handling
Pipelining is used to hide effects such as the latency of memory. It allows execution of multiple instructions to be overlapped and helps boost clock speed, as fewer logic steps are needed per cycle. Faster processor cores use more extensive pipelines that can be ten stages long or more. The drawback of long pipelines is high branch latency. If a branch is taken, it takes time to refill the pipeline with the instructions needed for the new branch.
Support for interrupts allows the processor core to suspend execution of the main program temporarily and handle other tasks. Interrupt handling is a key component for applications that need real-time response to events. Without it, the program code would have to contain loops that continually poll for information on external events, which would be far more wasteful of computational capacity.
Microprocessors for robot designers

A priority scheme employed by most processor cores allows interrupts from relatively unimportant peripherals to be ignored while the processor takes care of critical routines, such as transferring control from one task to another or the input from a critical interrupt. The result is a highly flexible architecture that can handle many different types of real-time application.
An important and specialised variant of the microprocessor for robot designers is the digital signal processor (DSP). This is a processor core that adds instructions and execution hardware optimised for signal-processing algorithms such as filters and fast Fourier transforms. Such instructions include fast fused multiply-add operations that are found in practically all DSP algorithms. Because DSP code operates on data structures such as matrices and vectors, it is relatively easy to parallelise the work. This has led to the implementation of single-instruction, multiple-data (SIMD) execution units that perform the same operations – such as multiply-adds – on multiple elements of an array at once. The result is much higher speed for comparatively little additional complexity or cost.
An MCU includes a number of integrated peripherals that are arranged around the processor core. Typically, in an industrial or robotics-oriented MCU, the peripherals range from memory arrays to advanced timer-trigger units, which are used to offload the burden of pulse width modulation (PWM) from the microprocessor. PWM is a core component of almost all motor-control strategies and so features prominently in robotic design. Other system-on-chip (SoC) devices add more features around an MCU such as wireless transceivers, dedicated encryption and authentication logic and graphics accelerators.
Control and hardware
The use of intelligent peripherals also illustrates an increasingly important design principle for robots: the exploitation of distributed control and hardware acceleration. A microprocessor can be used to implement PWM control, but it is often a poor allocation of resources. The core of the problem is that the software repeatedly has to switch power between transistors in the half-bridge that controls current flow to a motor after pre-programmed intervals. Interrupts from a real-time clock or counter can readily trigger handlers to switch power state and then configure the timer for the next cycle. But this results in a high interrupt frequency for what is an extremely simple sequence of operations.
A PWM controller combines timer and switching logic, which removes the requirement to have the microprocessor core interrupted for each switching operation. Software only needs to update the timers periodically to set the required PWM duty cycle. Thanks to a comparatively small amount of additional logic that can operate independently of the processor for substantial periods of time, software efficiency is greatly enhanced. The architecture has a common theme, with other hardware-offload mechanisms that will become increasingly important in robotic design. Hardware peripherals take care of frequent events in real time; software sets policy for those peripherals.
With hardware peripherals, designers are limited to the functions offered by IC suppliers, although the inclusion of sequencers based on hardware state machines increases their flexibility. For example such sequencers can read values from an A/D converter, transfer data values to main memory using direct memory access (DMA), and set and reload timers, all without involving the CPU core. However, the options remain limited.
FPGA in robotics
The field-programmable gate array (FPGA) provides a way to create custom hardware peripherals that can be optimised to specific robotic-control and machine-learning functions.
The core of most FPGA architectures is a programmable look-up table that can be configured to implement any logic function that can be expressed as a truth table. Using programmable switches in the interconnect fabric, the look-up tables are wired together into complex combinational logic circuits. Typically, each look-up table is accompanied by one or more registers and additional support logic, such as carry-chain inputs and outputs, to make it possible to implement arithmetic adders efficiently. Together, these functions make up a logic block that is replicated many times across the FPGA.
A drawback compared to fully customised logic is that their silicon efficiency is much lower. It takes 10 to 20 times as much silicon area to accommodate a logic circuit on an FPGA fabric compared to a custom, standard-cell implementation.
However, most FPGAs support reprogramming of the logic array even in a running system. This makes it possible to share resources by having accelerators dynamically loaded into the fabric only when they are needed. This approach also allows greater flexibility in the end design, enabling it to support new hardware and additional features.
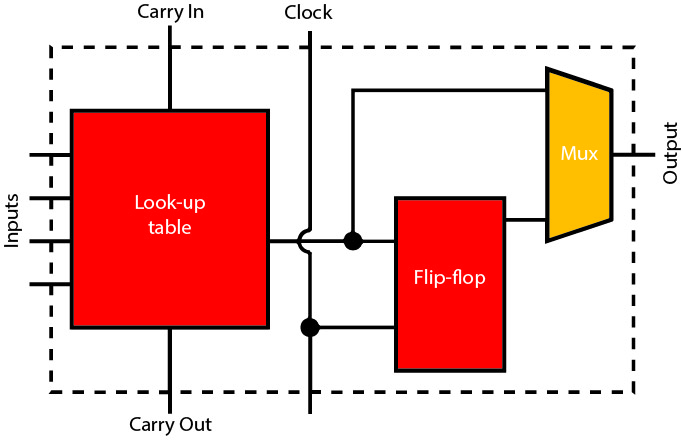
Since their introduction in the 1980s, FPGAs have acquired other features that improve overall density. Memory blocks allow the creation of buffers and caches close to the programmable logic. These have been joined more recently by DSP engines. In many cases, the DSP engines are implemented using a building-block approach, composed of 8-bit or 16-bit units, that allows them to be combined to support higher-precision datatypes.
DSP units make FPGAs highly suitable for processing the inputs from sensors that produce large amounts of data, such as cameras, radar and other types of image sensors. A typical application is to use a combination of DSP units and logic accelerators to handle algorithms such as image warping and lighting compensation that provide more consistent inputs to machine-learning and similar functions. These functions can be coordinated by custom microprocessor cores implemented in the programmable fabric, which act as microsequencers for the different processing primitives.
Leveraging GPUs, VPUs and Multi-Processing
Another option, particularly for image-processing tasks, is to employ a graphics processing unit (GPU) or vision processing unit (VPU). These contain highly parallelised DSP engines optimised for image processing. For robots that need very high levels of environmental awareness, these dedicated units may be combined with multiple CPUs – sometimes on the same chip, as a heterogeneous multi-core SoC.
The use of multi-processing can also be harnessed to improve overall reliability and safety. A problem for any computer-based design is its reliance on memory technologies that are vulnerable to ionising radiation. When ionising radiation hits the silicon substrate of an IC, it triggers a cascade of free electrons that flip the logic state of a transistor. In combinational-circuit transistors, the effect is usually transitory and captured only rarely.
However, memories and registers are more vulnerable to the change because of the way they recycle their contents to prevent stored data leaking away. Error checking and correction (ECC) codes help control the problem. The probability of a single-event upset increases with memory density, which makes it an increasing problem as these ICs continue to scale according to Moore’s Law. Also ECC may not catch all of the errors, which can lead to a program acting on incorrect data and, ultimately, a failure in control. In a robot interacting with the public, this cannot be allowed to happen.
Redundancy techniques and diverse processor design
Techniques such as redundancy deal with the problem by having individual processors check each other’s work.
The processors may be of the same type and run the same code. Checking logic compares their outputs and uses voting to determine which operation to allow or demands that operations are re-run until the processors agree.

The use of three processors with majority voting is more expensive but less intrusive, as re-running operations can incur unwanted delays. Modular redundancy can also be implemented at the gate level.
The processors in a redundant arrangement need not be identical. Some architectures have a less performant processor act as the checking engine. Rather than running the same software, it simply performs consistency checks and forces re-execution if a check fails or, in more extreme cases, a full reset.
To minimise the chances of systematic design errors creeping into the equation, duplicated processors may be designed and implemented in different ways. This is a technique used on some multi-core SoCs developed for automotive safety systems.
Architectural options for robot designers
Robot designers can now choose from a wide range of architectural options that can take them from simple designs through to highly flexible machines that can react intelligently to problems and obstructions and keep running smoothly.




